CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. The CLIP (Contrastive Language-Image Pre-training), an image-language pre-training model, has demonstrated the power of visua
arxiv.org
Clip의 경우 Image-Text 간의 유사도를 계산하는 방식
일반적으로 Video Retrieval Task에서는 Video-Text 간의 특징을 정렬하는 것이 핵심
그러나 비디오의 시간적 관계(혹은 인과성)을 고려하는 데에는 어려움이 있음
Clip4Clip에서는 비디오를 개별 프레임 단위로 처리하면서도, 다양한 방식으로 시간적 정보를 반영하도록 설계
1. Introduction
효과적인 비디오 검색을 위한 Video Retrieval 필요성 대두
기존 video-text retrieval 관련 연구의 인풋 형태: raw video(pixel-level), video feature(feature-level)
- 특징(feature)-레벨 접근 (Feature-Level Approach)
- 최근 연구들은 특징 레벨 접근을 많이 사용
- Howto100M과 같은 대규모 비디오-텍스트 데이터셋으로 사전 학습된 모델을 주로 활용
- 캐시된(cached) 비디오 특징을 활용하며, 별도의 비디오 특징 추출기(video feature extractor)를 통해 사전 생성된 특징을 사용
- 사전 학습된 특징 추출기의 성능에 의존하므로, 특징 추출기가 고정되면 학습을 비디오 인코더로 다시 전달할 수 없음
- 픽셀(pixel)-레벨 접근 (Pixel-Level Approach)
- 비디오의 원본(raw video)을 직접 입력하여 학습하는 방식
- 이 방식에서는 비디오 특징 추출기와 텍스트 인코더를 함께 학습(joint training) 하며, 모델이 직접 비디오 특징을 학습
- 특징 추출기의 크기에 따라 성능이 결정되는 단점 존대
- 픽셀 레벨 접근 방식의 새로운 시도
- ClipBERT - sparse sampling(일부 짧은 클립만 샘플링하여 학습, 엔드 투 엔드 학습 가능)
- Frozen - 이미지를 단일 프레임으로 간주하여 학습, curriculum learning schedule
사전학습된 CLIP 모델을 활용하여 비디오-텍스트 검색(video-text retrieval)을 수행
CLIP 모델 위에 유사도 계산기(similarity calculator)를 설계하여, 비디오와 텍스트 간의 유사도를 계산하는 세 가지 방식을 실험
인사이트
- 비디오 인코딩을 위해 단일 이미지(single image)는 충분하지 않음
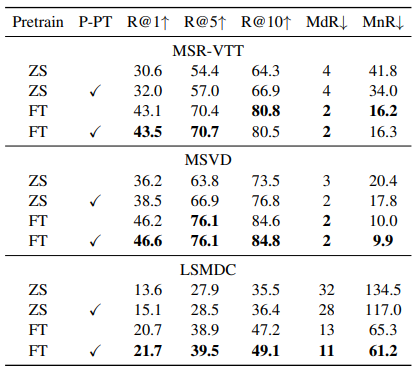
- 대규모 비디오-텍스트 데이터셋에서 Post-Pretraining이 필요함
- 작은 데이터셋에서는 추가 학습 없이 Mean-Pooling이 효과적, 큰 데이터셋에서는 추가적인 학습(예: Self-Attention)이 필요
- 최적의 하이퍼파라미터를 철저히 분석하여 최상의 설정을 보고함
2. FrameWork
$x^{a}+1$
비디오 세트 $v_i \in V$, 텍스트 세트 $t_j \in T$에 대해
비디오 $v_i$와 캡션 $t_j$의 유사도를 구하는 함수 $s(v_i, t_j)$를 학습시키는 것이 목적
이때, 비디오 $v_i$는 $|v_i|$개의 프레임으로 구성
$v_i = \{ v_i^1, v_i^2, \dots, v_i^{|v_i|} \}$
이때, 비디오 vi는 |vi|개의 프레임으로 구성


12 개의 층을 가진 VIT-B/32와 패치 사이즈 32인 비디오 인코더를 사용
- 이미지를 겹치지 않는(non-overlapping) 작은 패치(patch)들로 분할.
- 각 패치를 1D 토큰(token)으로 변환하는 선형 투영(linear projection)을 수행
- Transformer 아키텍처를 사용하여 이미지 내 패치 간의 관계를 학습
- [CLS] 토큰의 출력을 이미지 전체의 표현(representation)으로 사용
- 이를 통해 표현 $Z_i = \{ z_i^1, z_i^2, \dots, z_i^{|v_i|} \}$ 생성
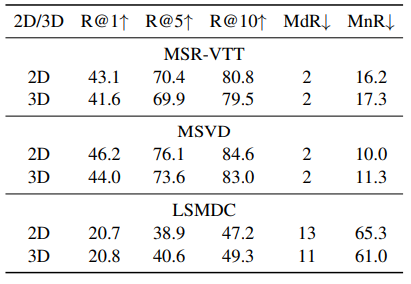
2D Linear Projection과 3D Linear Projection 두 가지 유형의 선형 투영 방식 연구
ViT의 Flattened Patches에 대한 선형 투영을 2D 선형으로 간주하며, 각 2D 프레임 패치를 독립적으로 임베딩(embedding)
이러한 2D 선형 방식은 프레임 간의 시간적 정보(temporal information)를 반영하지 못함
3D 선형 투영을 적용하여 시간적 특징(temporal feature) 반영
3D 선형 투영은 패치를 시간 차원까지 포함하여 임베딩하는 방식
3D 선형 투영은 [t × h × w] 크기의 3D 컨볼루션 커널을 사용하여 학습을 수행
(2D에 t(temporal)이 추가된 형태)
클립 텍스트 인코더 그대로 사용
We directly apply the text encoder from the CLIP to generate the caption representation.
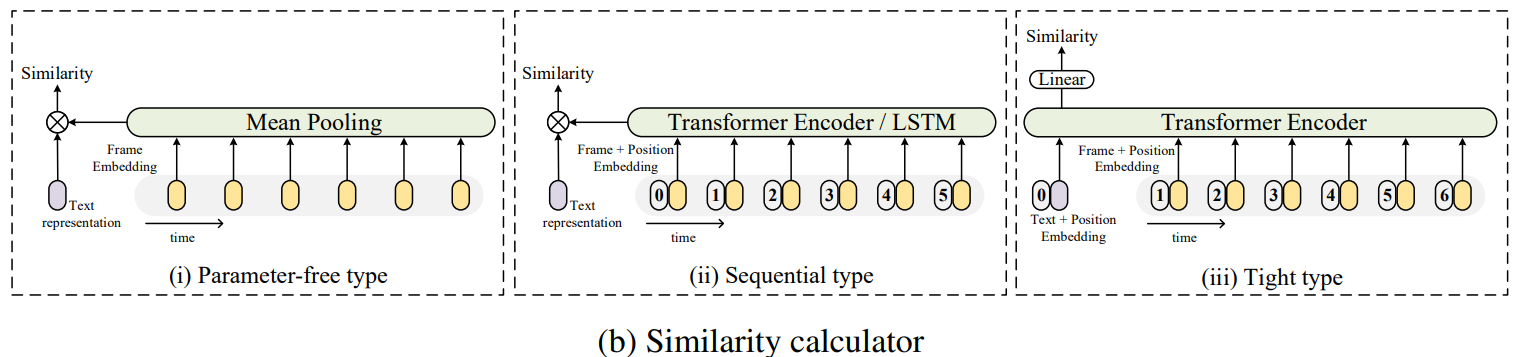
- Parameter-free type
- 추가적으로 학습해야할 파라미터가 추가되지 않는 방법, 단순 mean pooling
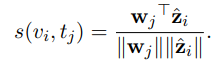
- Sequential type
- 프레임 사이의 순차적 정보를 사용하는 방식
- LSTM, Transformer 등을 사용하여 프레임 간 시간적 의존성(temporal dependency)을 모델링
- LSTM, Transformer의 히든 스테이트를 비디오 표현으로 사용하여 mean pooling 수행
- Tight type
- 트랜스포머 인코더(Self-attention layer)를 이용하여 중요한 프레임에 가중치를 부여하는 방식
- 캡션과 비디오 프레임 임베딩 z를 결합(concat)한 U 생성
- U를 트랜스포머에 입력 / P는 Positional Embedding, T는 BERT Segment Embedding
- 마지막 층의 첫 번째 토큰 출력을 입력으로 받아 두 개의 선형 투영층과 ReLU 활성화 함수를 거쳐 최종적인 유사도 점수를 계산
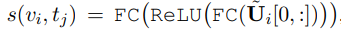
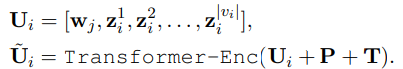
2.4 Training Strategy
symmetric cross entropy loss 적용
비디오에서 텍스트로 검색에서의 손실과 텍스트에서 비디오로 검색의 손실의 합
두 개의 손실을 대칭적으로 적용하여 비디오와 텍스트가 서로 일관되도록 학습
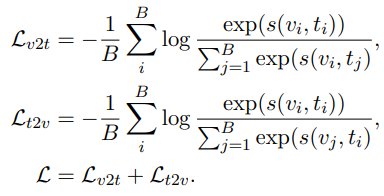
3. Experiments
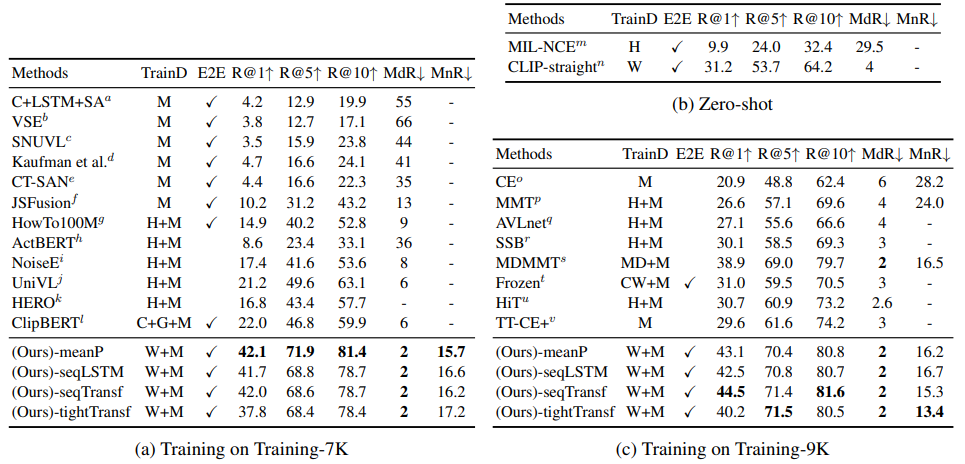
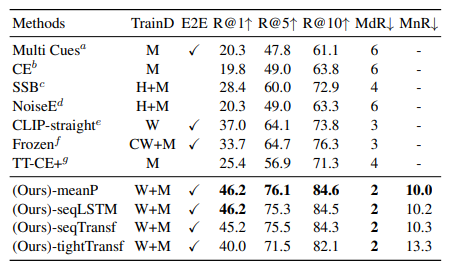
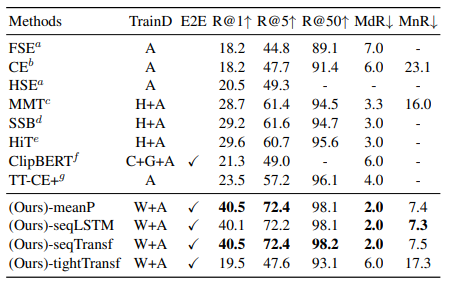
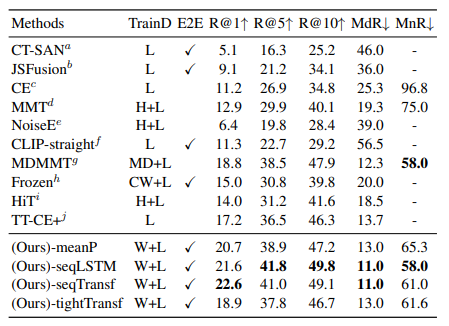
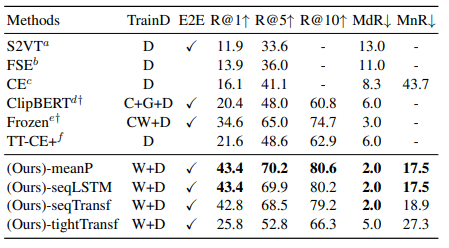
We validate our model on five datasets: MSR-VTT, MSVC, LSMDC, ActivityNet, and DiDeMo
M: MSR-VTT
H: HowTo100M
W: WIT
C: COCO Captions
G: Visual Genome Captions
'인공지능 > Paper Review' 카테고리의 다른 글
| [Paper] CLIP - Learning Transferable Visual Models From Natural Language Supervision (0) | 2024.08.13 |
|---|