이 글에서는 OpenAI의 유명 모델인 CLIP이 소개된 논문 Learning Transferable Visual Models From Natural Language Supervision에 관해 리뷰해보려 한다.
🟥 CLIP
해당 논문에서 소개하는 모델이 CLIP이라고 불리는 이유는 논문에서 'which we call CLIP, for Contrastive Language-Image Pre-training' 라고 소개하고 있기 때문이다. 해당 모델은 나무위키에도 있을 정도로 유명 모델이라고 할 수 있다.
https://namu.wiki/w/CLIP%20%EB%AA%A8%EB%8D%B8
왜 그런고 하니 CLIP은 텍스트와 이미지를 함께 처리할 수 있는 방법을 제시하였고 그로 인해 AI 그림 생성과 같은 많은 모델과 기술의 기반이 되어 관련 분야의 연구를 촉진했기 때문이다.
• 비전 모델의 한계
CLIP이 등장한 2021년 이전의 비전 모델과 자연어 모델의 발전 방향을 생각해보면 CLIP이 왜 혁신적이었는지 알 수 있다. 처음 딥러닝 모델이 손글씨를 인식하고 식별하는 등 비전 태스크부터 시작했음에도 불구하고 자연어 모델은 트랜스포머의 등장으로 엄청난 발전을 거듭했다. GPT, BERT와 같은 혁신적인 언어 모델이 등장하면서 초거대언어모델의 시대가 시작 됐다고 해도 과언이 아니다. 이런 언어모델은 사전 학습을 통해 대규모 데이터셋을 학습하고 이후 fine-tuning을 통해 효율적인 학습이 가능하고 일반화 성능도 높으며 적은 레이블에서도 좋은 성능을 보여준다.
CLIP논문 저자들은 이런 거대언어모델의 발전 방향처럼 비전 모델도 발전한다면 비전 모델이 큰 모델, 큰 데이터의 한계를 깨부술 수 있지 않을까 생각했다. 아무래도 비전 모델의 가장 큰 한계라고 하면 label 즉, 레이블링 된 데이터의 수가 적다는 것을 꼽을 수 있다. 자연어 모델의 경우 인터넷에 수많은 데이터들을 이용해 단어간의 종속성, 관계성을 학습시키면 되기 때문에 별도의 레이블링 작업을 요하지 않는다. 그러나 비전 모델의 경우 이미지 하나하나에 레이블링이 필요하고 이는 수동으로 이루어지기 때문에 대량의 이미지 데이터셋을 확보한다는 것은 굉장히 어려운 일이다. 그래서 저자들은 아주 큰 데이터셋을 사용하면 이런 비전 모델의 한계를 타파할 수 있지 않을까 생각하게 된 것이다.
- 자연어 Supervision
비전 모델의 한계를 타파하기 위해 그들이 선택한 방법은 레이블링에 시간을 투자하지 않고 인터넷에서 데이터를 모으는 방법을 선택한다. 물론 인터넷에 있는 모든 이미지 데이터가 라벨이 존재하지는 않는다. 그리고 설령 라벨이 있다고 하더라고 그 라벨이 정확한 라벨인지 보장할 수 없고 확인하는데 시간이 또 소요된다는 문제가 있다. 그래서 그들은 자연어를 Supervision으로 사용하는 방법을 채택했다. 이는 모델에게 이미지를 설명해주는 방법으로 인터넷상에서 이미지를 설명하는 자연어 문장을 그래도 Supervision으로 사용하는 방법이다.
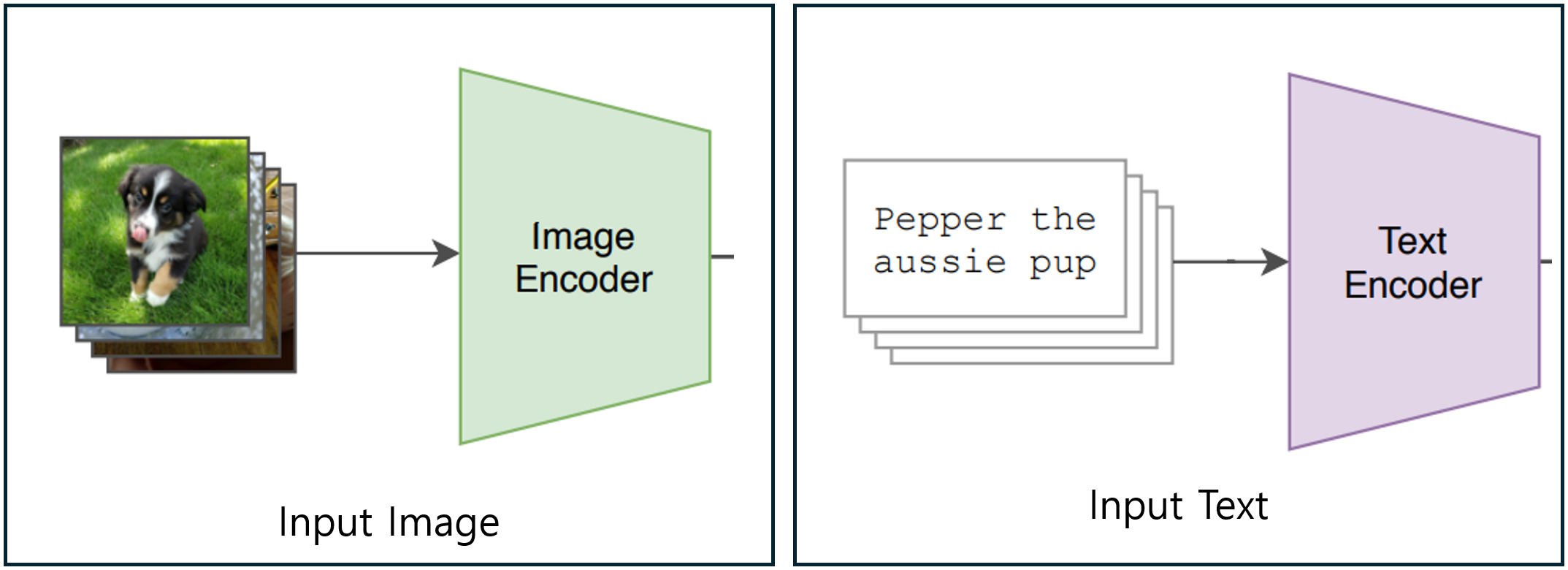
상기 이미지와 같이 입력되는 이미지에 dog, puppy와 같은 label이 아니라 상황을 설명하는 자연어 문장을 그대로 label로 사용해 입력으로 사용되는 것이다. 이렇게 데이터셋을 구축하면 인터넷에 돌아다니는 많은 데이터를 쉽게 수집할 수 있으니 대량의 데이터셋을 구축할 수 있다는 것이 그들이 설명하는 바이다. 실제로 저자들은 이렇게 4억장 정도의 이미지-자연어 데이터셋을 구축했다고 한다. 이 두 형태의 입력이 처리되는 방법은 나중에 더 자세히 이야기 하겠다.
- Contrastive Learning
다음은 CLIP에서 이러한 대규모 이미지-텍스트 페어 데이터셋을 학습하는지 이야기 해보자. 일반적인 이미지 데이터만을 활용한다면 Cross Entropy Loss 같은 손실 함수를 이용하여 모델을 업데이트 할 수 있을것이다. 그러나 CLIP에서는 텍스트를 함께 학습시켜야 하기 때문에 이러한 방법이 불가능하다. 왜냐하면 텍스트의 경우 데이터마다 길이가 다르고 이미지와 달리 고정된 클래스로 구분되지 않아 Softmax와 같은 함수를 사용할 수 없기 때문이다. 그래서 CLIP의 저자들은 Contrastive Learning이라는 방법을 사용해 모델을 학습시켰다. Contrastive Learning은 CLIP의 아키텍처를 보면 이해가 쉬울 것이다.
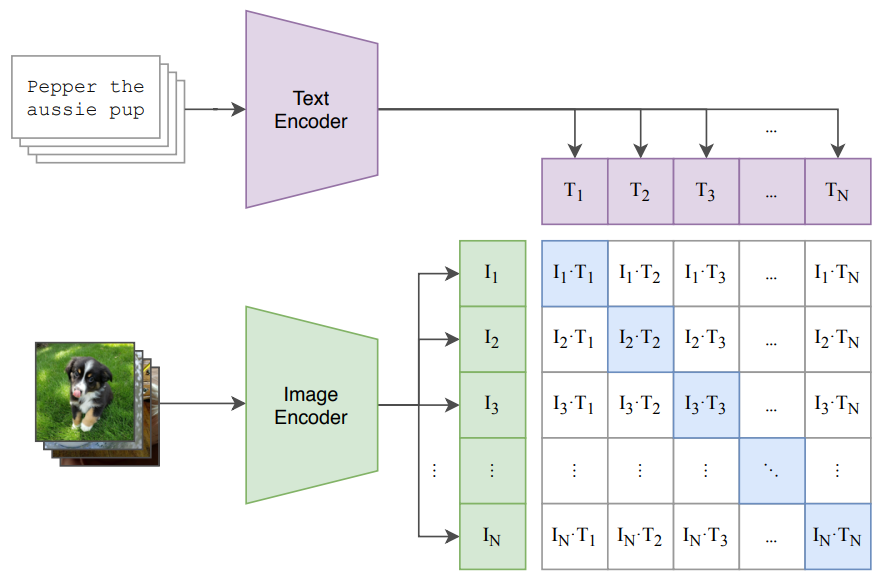
Contrastive Learning은 라벨 없이 데이터를 학습하는 Self-supervised Learning 방법론 중에 한가지이다. ( Contrastive Learning ⊂ Self-supervised Learning ⊂ Representation Learning ) 쉽게 이해하자면 Contrastive Learning은 연관 있는 데이터 특징들끼리는 Feature Space 상에서 가깝게 위치시키고 관련이 없는 데이터끼리는 거리를 멀어지도록 embedding network를 학습하는 방법을 말한다. 이러기 위해서 CLIP에서는 이미지를 처리하는 인코더와 텍스트를 처리하는 인코더를 별개로 두어 각각의 특징을 추출하는 Two-tower Architecture를 채용했다. CLIP의 이미지 인코더에서는 ResNet 또는 ViT를 텍스트 인코더에서는 Transformer를 이용하였다. 각각의 인코더는 마지막 출력에서 고정된 크기의 임베딩 벡터를 생성해 서로 차원의 크기를 맞추고 이를 이용해 이미지와 텍스트간의 유사도를 구한다. 유사도의 경우 코사인 유사도를 이용하여 유사도를 계산한다. 텍스트의 경우 각 문장마다 길이가 다른데 이를 처리하는 방법이 positional embedding으로 아래 글을 읽어 보면 자세히 알 수 있다. https://bigsong.tistory.com/50
[딥러닝]Positional Encoding (with Positional Embedding)
Transformer 기반의 모델들이 우수한 성능을 보여주면서 그 활용도가 점점 높아지고 있다. 그리고 Transformer 모델을 소개하는 논문 "Attention is All You Need"에서 Positional Encoding라는 방법 또한 처음 등장
bigsong.tistory.com
Contrastive Learning에 사용되는 손실 함수로는 Contrastive Loss로 일반적인 형태는 다음과 같다.

margin > Distance인 경우 로스값이 존재하고 Distance가 α만큼의 크기가 되도록 CNN의 파라미터 업데이트
margin < Distance인 경우 max함수를 거치면 Loss가 0이므로 가중치가 업데이트 되지 않음
- Zero Shot Prediction
이런 CLIP의 이미지-텍스트 페어 학습 방법을 이용하면 다양한 시도가 가능해진다. 그 중 하나가 Zero Shot Prediction이다. Zero Shot Prediction은 Zero Shot 즉, 한번도 보지 않은 이미지에 대해 예측하는 테스크를 말한다. 이러한 방식은 기존의 이미지 분류를 위한 Supervised Learning 방식에서는 불가한 방법으로, 클래스가 정해져 있지 않은 경우에 대처를 할 수가 없기 때문이다. 그러나 CLIP은 Self-supervised Learning을 통해 이러한 시도가 가능한 것이다.

CLIP에서는 위의 그림처럼 텍스트를 미리 세팅해놓는다. 이는 클래스를 설명해주는 문장으로 표현하기 위한 것으로 모델의 학습과정에서 클래스를 학습한 것이 아닌 그림을 설명하는 텍스트를 학습했기 때문이다. 그 다음으론 이미지 인코더와 텍스트 인코더를 이용해 각각의 특징을 추출한다. 그리고 추출된 이미지의 특징과 가장 유사한 텍스트 특징을 찾아낸다. 여기서 가장 유사한 텍스트는 이미지를 가장 잘 설명하는 문장에 해당 될 것이다. 이러한 방법을 통해서 CLIP은 고정되지 않은 개수의 클래스에 대해 예측이 가능하다. 이는 이미지가 클래스를 구분하는 것이 아닌 이미지의 특징 벡터와 상황을 가장 잘 설명하는 텍스트의 특징 벡터가 정렬되도록 CLIP 모델이 학습하기 때문이다.
https://ffighting.net/deep-learning-paper-review/multimodal-model/clip/
'인공지능 > Paper Review' 카테고리의 다른 글
| [Paper] CLIP4Clip: An Empirical Study of CLIP for End to End Video ClipRetrieval (0) | 2025.02.26 |
|---|