Transformer 기반의 모델들이 우수한 성능을 보여주면서 그 활용도가 점점 높아지고 있다. 그리고 Transformer 모델을 소개하는 논문 "Attention is All You Need"에서 Positional Encoding라는 방법 또한 처음 등장하게 되었다. 이후 Transformer 기반의 자연어 모델들이 우수한 성능을 보였고 BERT 모델에서는 Positional Embedding을 사용하였다. 그러나 요즘 Positional Encoding과 Positional Embedding에 차이가 있음에도 이를 혼용하여 사용하고 있는것 같아 이에 관해 자세히 정리해보려고 한다.
🟥 Encoding / Embedding
먼저 Encoding과 Embedding이 무엇인지 어떤 차이가 있는지부터 확인해보자. 둘 다 데이터를 변환을 목표로 한다는 점에서 동일하지만 그 목적과 방식에서 분명한 차이가 있다.
• Encoding
Encoding(인코딩)은 데이터를 시스템에서 이해하고 처리할 수 있는 형식으로 만들기 위해 데이터를 다른 형식으로 변환하는 과정을 의미한다. 일반적으로 단순하고 직접적인 변환을 수행하며, 데이터의 구조나 의미를 최대한 유지한다는 특성이 있다. 그리고 변환된 데이터의 경우 일반적으로 고정된 형식을 가진다. 그렇기에 인코딩의 특징은 Fixed라 할 수 있다. 범주형 데이터를 수치형으로 변환하거나, 텍스트 데이터를 이진 형식으로 변환하는 작업이 이에 해당한다.
• Embedding
Embedding(임베딩)은 고차원 데이터를 저차원 벡터로 변환하는 기법이다. 이는 주로 범주형 데이터를 연속적인 벡터로 변환하는데 사용되며, 데이터의 의미적 유사성을 벡터 공간에 반영한다. 이에 따라 벡터 간의 유사성은 데이터 간의 의미적 유사성을 반영할 수 있게 된다. 임베딩 벡터의 차원은 고정되어 있으며, 벡터의 차원은 학습 과정에서 결정된다. 이러한 점 때문에 임베딩의 특징은 learnable이라 할 수 있다. 학습을 통해 데이터를 변환하며, 벡터 간의 유사성이 데이터 간의 의미적 유사성을 반영하기 때문이다.

• Dimensionality Reduction
그럼 또 헷갈릴 수 있는 부분이 임베딩은 고차원 데이터를 저차원 벡터로 변환하기 때문에 차원 축소에 해당하지 않나라고 생각할 수 있지만 이 또한 다른 개념이다. 임베딩은 주로 범주형 데이터를 벡터화하여 의미적 유사성을 반영하려 하는 반면, 차원 축소는 고차원 데이터를 저차원으로 축소하여 분석 및 시각화 등 그 목적에서 차이가 있다. 그리고 임베딩은 학습 기반의 방법을 통해 데이터 간의 의미가 반영된 벡터가 생성되는 반면, 차원 축소는 통계적 방법이나 수학적 변환을 통해 데이터를 변환하기 때문에 그 방법에서도 차이가 존재한다.
🟥 Positional Encoding / Positional Embedding
이제 Positional Encoding과 Positional Embedding에 대해 알아보자. 이 둘을 VS로 표현하지 않는 이유는 Positional Embedding은 Positional Encoding의 한 종류로 볼 수 있기 때문이다. ( Positional Embedding ⊂ Positional Encoding)
• Positional Encoding
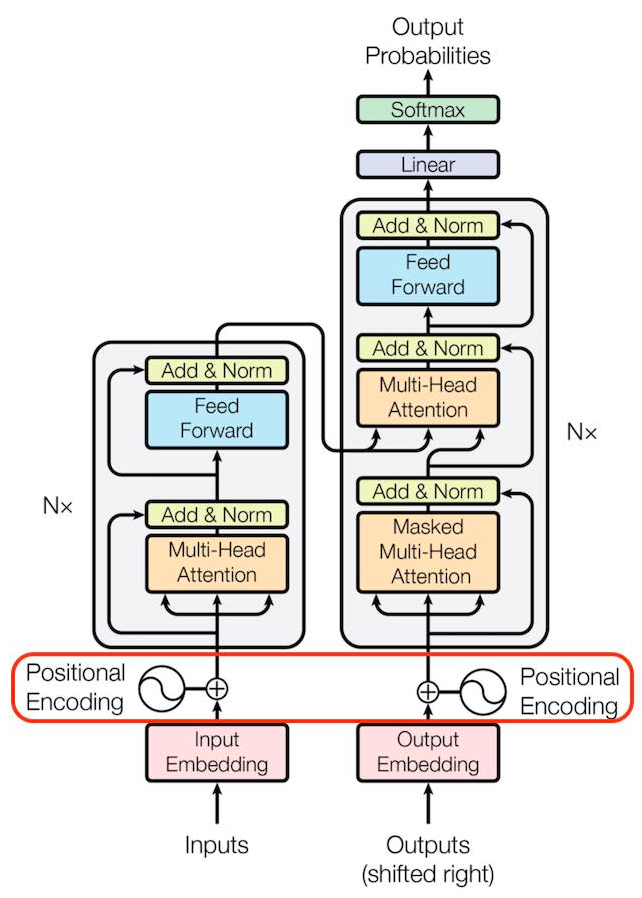
Positional Encoding은 Transformer 모델에서 입력 시퀀스의 순서를 인식하게 하기 위해 사용하는 방법이다. 이는 Attention Mechanism의 동작 방식 때문에 생겨난 방법이다. Attention의 경우 순차적으로 데이터를 처리하지 않고 병렬적으로 데이터를 처리하기 때문에 입력 시퀀스의 정보가 별도로 필요하다는 특징이 있다. 이를 위해 Transformer에서는 Positional Encoding을 이용하여 각 단어의 위치 정보를 모델에 제공하려한 것이다.
여기서 말하는 Positional Encoding은 Fixed Positional Encoding으로 입력 시퀀스의 각 위치에 대해 고정된 고유한 벡터를 제공한다는 의미이다. 이는 Sine, Cosine과 같은 Sinusoid 함수를 사용하여 위치 정보를 인코딩한다. Positional Encoding 𝑃𝐸는 각 위치 𝑝𝑜𝑠와 임베딩 차원 d 입력 시퀀스 𝑖에 대해 다음과 같다.

예를 들어, 임베딩 차원이 512인 경우, 각 단어의 위치에 대해 사인/코사인 값을 계산하여 512차원의 벡터를 생성하는 것이다. 여기서 확인해야 할 것은 Sinusoid 함수의 특징에 의해 다른 위치의 시퀀스에 대해 동일한 인코딩이 발생할 수 있지만, 함수 입력 전 위치 𝑝𝑜𝑠를 차원 d와 입력 시퀀스 𝑖를 이용해 변화를 줌으로써 각 위치에 대해 고유한 인코딩이 생성되도록 한다. 이로 인해 낮은 차원에서는 주기가 짧고, 높은 차원에서는 주기가 길어지게 된다. 결과적으로 Positional Encoding에 의해 생성된 것은 벡터이기 때문에 Sinusoid 함수의 주기에 의한 같은 인코딩이 발생할 염려가 없는 것이다.
• Positional Embedding
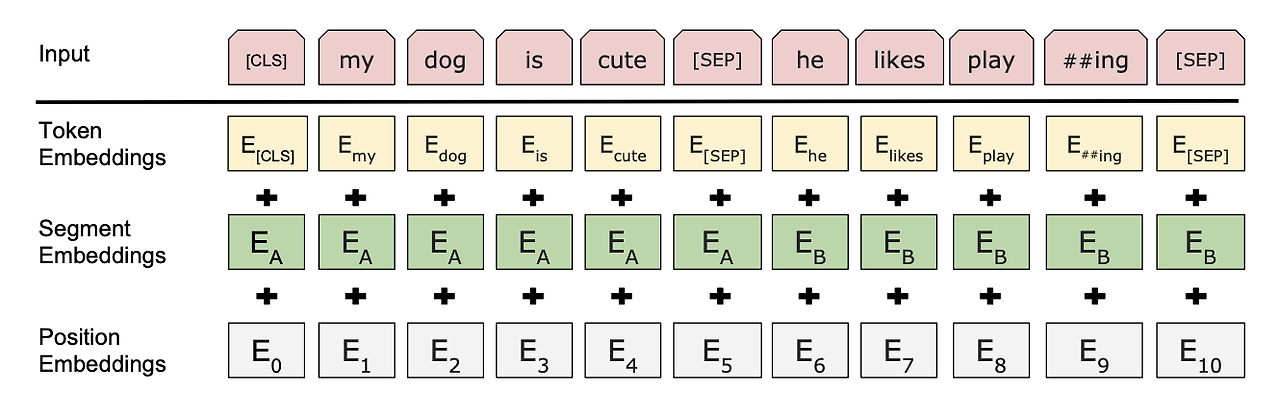
Positional Embedding은 BERT 모델에서 사용하는 인코딩 방식으로 Transformer의 Positional Encoding과 비교되는 가장 큰 특징은 learnable하다는 것이다. Positional Embedding에서는 각 위치에 대해 고정된 값을 사용하는 대신, 위치 정보를 학습 가능한 임베딩 벡터로 표현한다. 이는 모델이 학습하는 과정에서 고정된 수식을 사용하지 않고 최적의 벡터를 학습하게 된다. 이러한 과정은 Additive Form에 의해 이루어 지는데 Additive Form은 입력 시퀀스의 각 단어에 대한 임베딩 벡터와 위치 정보를 인코딩한 벡터를 더하여 최종 입력 벡터를 생성한다.
이 둘의 개념을 간단하게 비교하여 표로 정리하면 다음과 같다.

'인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝]OpenCV Python의 Filter (1) | 2024.07.30 |
|---|---|
| [딥러닝] 이미지 분류를 이해하기 위해 읽어야 하는 논문 Top10 (0) | 2022.03.21 |
| [딥러닝] 이미지 인식, 분류, 분할 - 컴퓨터 비전 (1) | 2022.03.15 |


