딥러닝에 관해 공부를 시작할때 가장 먼저 접하는 분야가 이미지 분류일 것이다.
가장 흔하게 연구에 사용하는 데이터셋인 MNIST나 CIFAR-10 같은 경우도 모두 이미지 분류에 속하는 것을 알 것이다.
이런 이미지 인식(Visual Recognition) 영역에 대해서 이야기 해보려 한다.
이미지 인식(Visual Recognition)
이전 글에서 인공지능의 시작과 발전에 대해 설명했었다.
https://bigsong.tistory.com/43?category=986883
[인공지능] 인공지능, 머신러닝, 딥러닝에 대하여(역사)
인공지능이란 인공지능의 등장 인공지능이란 용어을 처음 사용한 존 맥카시(John McCarthy)는 인공지능을 'Intelligence한 기계를 만드는 과학, 공학'이라고 정의하였다. 순수하게 그 의미를 해석해보
bigsong.tistory.com
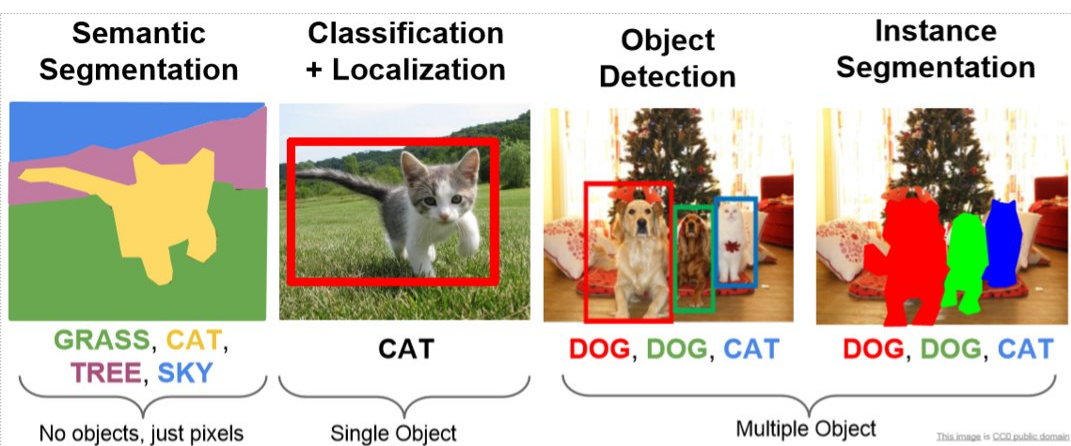
해당 글에서 언급한 대로 딥러닝 시대의 시작은 이미지 인식 경진 대회인 ILSVRC로부터라고 봐도 될 것이다. 해당 대회의 목적이 이미지 데이터를 카테고리에 맞게 분류하는 것이었기 때문에, 자연스럽게 딥러닝의 기반이 이미지 분류에서부터 시작되었다고 봐도 무방하지 않을까라고 생각한다. 해당 대회에서는 이미지를 정확하게 분류해내는 이미지 분류(Image Classification) 영역에 집중하고 있지만, 현재의 이미지 인식 분야에서는 객체 탐지(Object Detecting)와 이미지 분할(Image Segmentation) 영역이 새로 등장하였다. 특히 Segmentation의 경우에는 Semantic segmentation과 Instance segmentation으로 나누어 볼 수도 있다. 그리고 객체 탐지의 경우 이미지에 한정되지 않고 영상에서도 객체 탐지를 적용해 사용하고 있다. 현재는 컴퓨터가 이런 이미지와 영상에서 인간의 시각이 할 수 있는 일들을 자율적으로 수행할 수 있도록 연구하는 분야에 대해서 '컴퓨터 비전(Computer Vision)'이라고 부르고 있다.
이미지 분류(Image Classification)
이미지 분류는 컴퓨터가 이미지 속의 특정 대상 혹은 물체가 무엇인지 분류해내는 것이다. 위에서 언급한 것처럼 딥러닝의 시작이 이 이미지 분류에서부터 시작되어 최근에 소개된 새로운 이미지 분류 알고리즘들의 경우, 인간의 인식 오류율보다 낮은 오류율을 보여주고 있다. 90년대에 등장한 LeNet에서 시작해 2012년엔 AlexNet, 그 이후에 VGGNet, GoogLeNet, ResNet 등등 오류율은 크게 감소하였고 현재는 0.0001%의 오류율이라도 높이기 위한 다양한 연구가 진행되고 있다.
CNN(Convolutional Neural Network)
이미지 분류에서 CNN에 대해 빼놓고 이야기 할 수 없을 것이다. MLP의 한계를 극복하기 위해 등장한 CNN은 인간의 뉴럴 네트워크를 모방해 만든 것으로 Convolution과 Pooling을 반복하여 이미지의 특징을 추출해 낸 뒤, FC Layer(Fully
Connected Layer)를 통해 이미지의 class를 분류해 낸다.

CNN의 핵심은 위 이미지에서 나온 Feature extraction(특징 추출)을 어떻게 해내는가이다. 신경망 내부에서는 특징을 추출해 내기 위해 Convolution filter를 사용하는데 이 필터는 전체 이미지를 정해진 크기에 따라 움직이면서 필터의 크기에 따라 전체 이미지의 부분적인 특징을 학습하게 된다. 이후 분류하고자 하는 이미지를 넣게 되면 필터가 학습하고 있는 부분 이미지에 대한 특징과 유사한 정도를 판단하여 이미지를 분류해내게 되는 것이다.

위의 이미지는 MNIST 데이터 셋에 대한 이미지로 오른쪽의 Filter를 통해 왼쪽과 같은 Feature map을 얻을 수 있다. 이렇게 이미지의 특징을 무작위한 필터를 거침으로써 특징을 추출하는 것이 가능하다. 이미지 분류의 정확도를 높이고 싶다면 이렇게 필터를 거쳐서 확인되는 이미지의 특징을 두드러지게 하면 될 것이다. 이미지의 특징을 두드러지게 하기 위해서는 필터의 크기를 더 작게 하고 필터가 한번에 이동하는 범위를 작게 조절하면 더 세밀하게 특징을 뽑아낼 수 있을 것이다. 그러나 이렇게 필터의 크기를 줄이고 이동 범위를 줄이게 되면 학습해야 하는 양이 늘게 되고 이에 따라 연산량이 증가하면서 학습에 소요되는 시간이 증가될 것이다. 그리고 너무 자세하게 학습하다보니 과적합의 문제도 발생하게 될 것이다. 이러한 문제를 해결하면서 이미지의 특징을 더 잘 학습하기 위해 고안된 방법이 Pooling이다.
 |
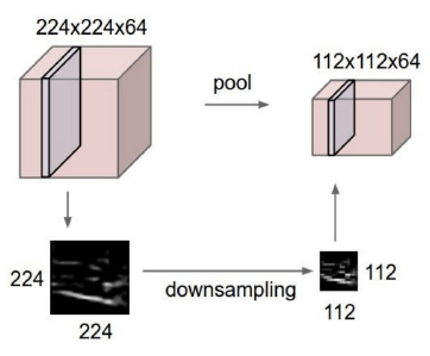 |
Pooling은 filter를 거쳐 얻은 feature map에서 다시 한번 특징을 표현해 낼 수 있는 값을 도출해내는 것을 말한다. 최대 풀링에서는 풀링 사이즈 내의 feature map 값들중 가장 큰 값을, 평균 풀링은 feature map 값들의 평균을 도출한다. 이렇게 Pooling을 적용하게 되면은 이미지의 크기는 줄이면서 해당 영역의 특징은 그대로 유지할 수 있기 때문에 앞서 말한 문제점들을 해결 가능하다.
이미지 분할(Image Segmentation)
이미지 분할은 Semantic segmentation과 Instance segmentation 2가지 영역으로 나눌 수 있다. 먼저 segmentation에 대해서 정리하자면 이미지 영역을 분할하여 원하는 object에 맞게 다른 영역과 구분가능하게 분할 해주는 것을 말한다.
보통은 원하는 object에 대해 영역의 색상을 다르게 하여 표시해준다.

그렇다면 Semantic segmentation과 Instance segmentation의 차이점은 무엇일까. 바로 이미지 내에서 원하는 object를 분류해 냈을때, 똑같은 object로 분류한 object들에 대해 다른 object로 판단하는가 같은 object로 판단하는가이다. 위의 사진에서 볼 수 있듯이 Semantic segmentation에서는 사진 속 의자들을 모두 같은 object로 인식하고 모두 파란색으로 표시해 구분지어 주었다. 한편 왼편의 Insatance segmentation의 경우 각 의자들에 대해 모두 다른 색상으로 구분함으로써 같은 범주의 의자임에도 각각 다른 object로 분류해주었다. 이렇게 다르게 이미지를 분할해 내는데에는 각각의 특성에 차이가 있기 때문이다. Semantic segmentation에서는 전체 이미지에서 각각의 픽셀이 특정 범주에 속하는지 만을 판단하지만 Instance segmentation에서는 각 픽셀별로 object가 있는지 없는지 만을 판단한다. 쉽게 생각하면 Semantic segmentation은 이미지 내에서 object를 class를 분류해낸 뒤 분할해 내는 성격이고 Instance segmentation은 분류해낸 각각의 object를 따로 관리하는 성격으로 보면 되겠다.
객체 탐지(Object Detecting)
오브젝트 디텍팅은 이미지 혹은 영상에서 찾고자 하는 대상(object)에 대해 분류해내는 기술이다. 오브젝트 디텍팅의 흐름은 먼저 이미지나 영상에서 물체가 있는지 없는지 인식(Object Recognition)하는 것에서 시작한다. 이후 인식한 물체에 대해 그 물체가 무엇인지 분류(Object Classification)하고 전체 이미지에서 해당 물체의 위치를 표시(Object Locallization)해준다. 만약 영상 데이터라면은 이 분류한 물체에 대해 추적하는(Object Tracking) 과정까지 포함된다.

전통적인 오브젝트 디텍션의 경우 Two-shot으로 이루어져 있다. 이 말이 무슨 뜻이냐면 물체를 검출하는데 2단계를 거쳐서 검출하기 때문이다. Two-shot으로 이루어진 이유는 위에서 말한 객체 검출의 흐름에서 보이듯이 물체를 인식하고 분류하는 두번의 단계를 거쳐야 하기 때문이다. 전체 이미지에서 물체가 어디에 있는지 인식하는 알고리즘과 해당 물체가 무엇인지 분류하는 알고리즘이 합쳐지지 않기 때문에 어쩔수 없이 두 단계에 걸쳐 구성될 수 밖에 없었고, 그러다 보니 연산량이 증가하게 되고 실시간성은 포기할 수 밖에 없다. 그러나 이는 YOLO 알고리즘이 등장하면서 One-shot이 가능하게 되었다. YOLO에 대해 자세하게 공부한 적은 없어 자세한 원리는 모르지만 기존의 물체를 인식해낸 다음 분류를 진행하는 두 단계 방식이 아닌 인식과 분류를 동시에 진행하는 방식이라고 한다.
이번 글에서는 이미지를 인식하고 이를 어떻게 처리하는지에 대한 컴퓨터 비전 영역에 대해서 알아 보았다.
참고
https://ganghee-lee.tistory.com/44
https://mickael-k.tistory.com/24
※틀린 내용이나 수정이 필요한 부분은 댓글 남겨주세요
'인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝]OpenCV Python의 Filter (1) | 2024.07.30 |
|---|---|
| [딥러닝]Positional Encoding (with Positional Embedding) (0) | 2024.07.25 |
| [딥러닝] 이미지 분류를 이해하기 위해 읽어야 하는 논문 Top10 (0) | 2022.03.21 |


