본격적으로 컴퓨터비전 영역에 대해 공부하기에 앞서 이미지 분류 알고리즘이 어떤 종류가 있는지 알아두면 좋을거 같아 이미지 분류와 관련된 논문 top10을 읽어보고 리뷰해보려고 한다. 새로운 알고리즘이 등장할 때마다 정확도를 높이기 위해 도입한 새로운 방법들이 소개되고 있다. 어떻게 이런 방법들이 생겨났고 어떤 효과로 인해 분류 알고리즘의 정확도를 높일 수 있었는지 각각의 논문들을 리뷰해보면서 알아보도록 하겠다.
1. LeCun, Yann, et al. "Gradient-based Learning Applied to Document Recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324.
-LeNet
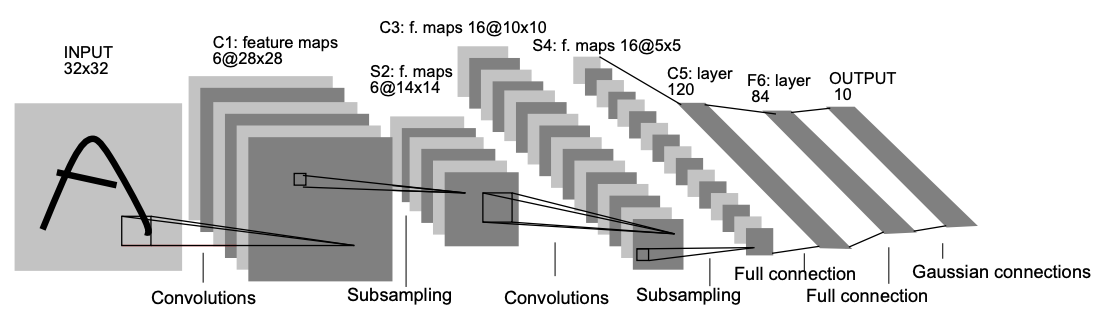
LeCun이 만든 CNN 초기 모형으로 Pooling, Padding, Activation function, Fully connected로 연계되는 일련의 과정을 사용했으며, MSE Loss를 활용했다. 해당 논문은 너무 옛날 논문이기도 하고 초기 구조를 제안했다는 점만 확인하고 논문 리뷰는 스킵!
2. Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems 25 (2012).
-AlexNet

알렉스넷은 이미지넷에서 주최하는 이미지 분류 대회인 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 2012년도에 우승한 알고리즘이다. 알렉스넷은 기존 이미지 분류 알고리즘에서 딥러닝이라는 개념을 적용한 알고리즘으로 진화한 모델로 이미지 인식 에러율을 10%대로 낮추며 본격적인 딥러닝 시대의 시작을 알린 알고리즘이라고 해도 무방하다. 멀티GPU를 이용해 데이터셋을 학습하는 방법과 ReLU 활성화 함수 적용, Dropout 적용 등 좋은 방법들을 많이 소개하고 있다.
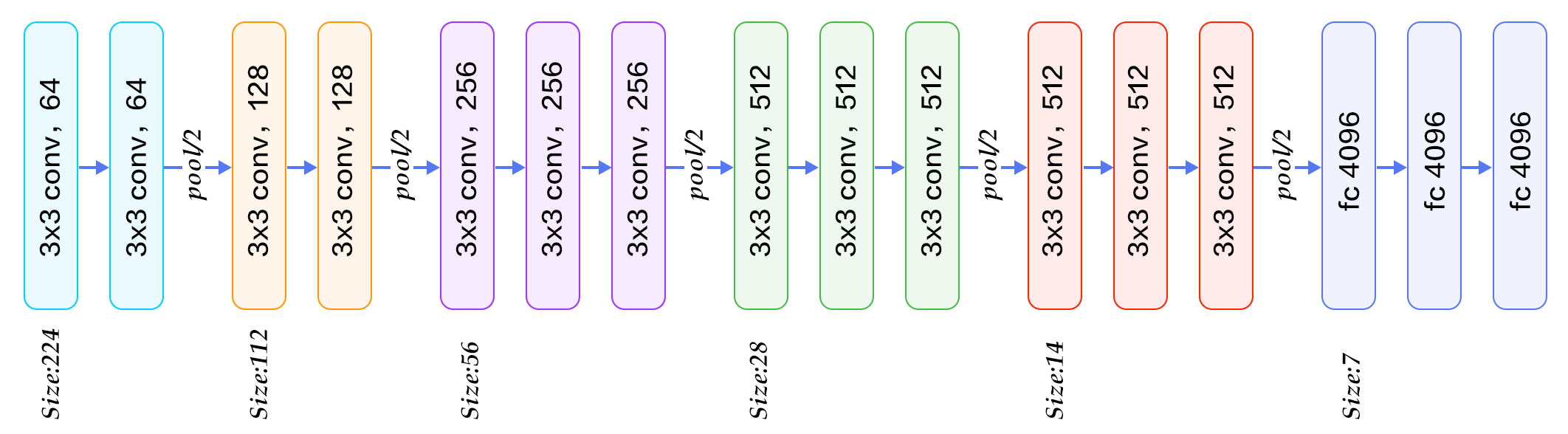
3. Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
-VGGNet
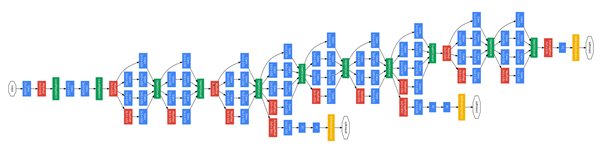
4. Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
-GoogLeNet
5. Ioffe, Sergey, and Christian Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift." International conference on machine learning. PMLR, 2015.
-Batch Normalization
해당 논문은 새로운 알고리즘을 소개하는 것이 아니라 데이터를 정규화하는 방법에 대해서 소개하고 있다. 논문에서 소개하는 정규화 방법을 이용하면 얻을 수 있는 효과로는 학습 속도를 개선하고 과적합을 예방할 수 있다고 한다. 또한 이전의 알고리즘에서 문제점으로 지적되던 기울기 소실 문제를 예방할 수 있다고도 한다.
6. He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
-ResNet
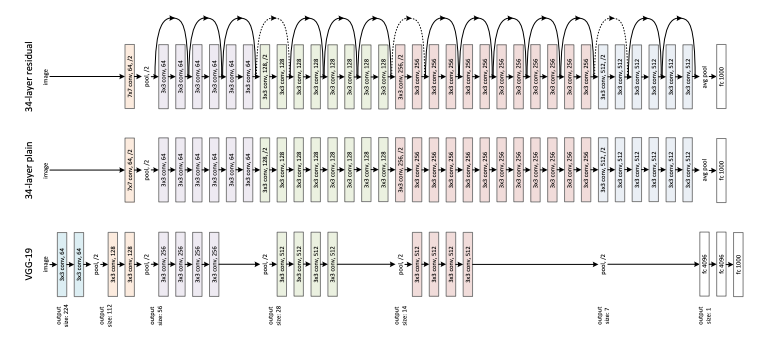
이 논문은 ResNet 알고리즘에 대해 소개하는 논문으로 잔차(residual)를 이용한 학습 방법을 소개하고 있어 이름을 ResNet이라고 한다. 잔차를 이용하여 모델이 학습시 얻을 수 었는 효과로는 기존의 알고리즘들보다 학습속도에서 개선된 모습을 보여준다고 한다. 그리고 잔차를 이용하여 최적화를 쉽게 하고 레이어를 더 깊게 쌓아 정확도를 높일 수 있는 방법에 대해서도 얘기하고 있다.
7. Chollet, François. "Xception: Deep learning with depthwise separable convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
-Xception
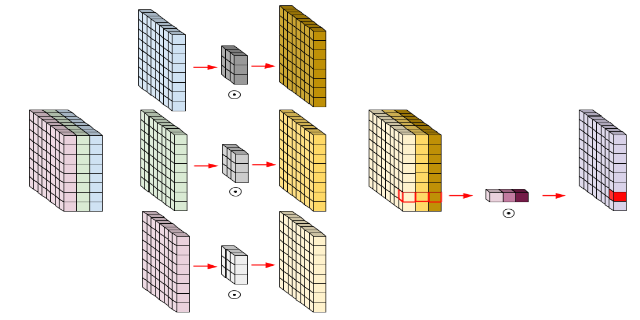
Xception은 Inception 모듈에 대한 고찰로 탄생한 모델로 기존 Inception 모델에서 채널, 공간, correlation을 분리하여 이를 depthwise separable conv로 강화한 모델이다. Xception은 완벽히 cross-channel correlations와 spatial correlations를 독립적으로 계산하기 위해 고안된 모델로 새로운 Inception 모듈을 제안한다.
8. Howard, Andrew G., et al. "Mobilenets: Efficient convolutional neural networks for mobile vision applications." arXiv preprint arXiv:1704.04861 (2017).
-MobileNets
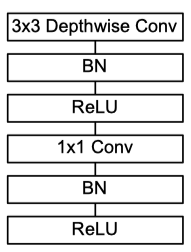
모바일넷은 모바일 기기에서 서빙 가능한 가벼운 모델을 만들기 위해 진행된 연구에 대한 내용을 담고 있다. 모바일넷의 핵심은 Xception에서도 등장했던 depthwise separable convolution을 이용해 파라미터 수를 줄이고 연산량을 줄여 가벼운 모델을 만들고자 했다는 것이다.
9. Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
-NasNet

나스넷은 새로운 검색 공간을 디자인하여 트랜스퍼할 수 있도록한 것이 가장 큰 특징이다. CIFAR-10 데이터셋에서 최고의 컨볼루션 레이어을 찾고, 이 레이어를 ImageNet 데이터셋에 적용하는 방식이다. 즉, 작은 데이터셋에서 학습한 최고의 결과를 더 큰 데이터셋에 적용하는 것이다.
10. Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." International conference on machine learning. PMLR, 2019.
-EfficientNet

에피션트넷에서는 모델의 정확도를 높이기 위해 조절하는 깊이, 너비, 입력 이미지 크기를 효율적으로 조절할 수 있는 compund scaling 방법에 대해 소개하고 있다. 이들 관의 일정환 관계를 찾아내서 수식으로 만들어낸다. 그리고 이를 통해 NAS(neural architecture search) 구조를 수정함으로써 모델의 예측 정확도를 높일 수 있다고 소개한다. 논문에 기재된 자료를 보면 알 수 있듯이 동일한 연산량을 가진 모델들을 비교했을때에도 에피션트넷의 정확도가 더 높은 것을 확인할 수 있다.
이렇게 이미지 분류와 관련된 10개의 논문들을 알아 보았다. 앞으로 해당 논문들을 읽어보고 리뷰하겠지만 일부 논문은 생략할 수도 있고 다른 논문이 추가될 수도 있겠다.
이외에도 읽어볼 만한 논문들
- SPPNet, He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." IEEE transactions on pattern analysis and machine intelligence 37.9 (2015): 1904-1916.
- DenseNet, Huang, Gao, et al. "Densely connected convolutional networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- ShuffleNet, Zhang, Xiangyu, et al. "Shufflenet: An extremely efficient convolutional neural network for mobile devices." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Bag of Tricks, He, Tong, et al. "Bag of tricks for image classification with convolutional neural networks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
참고
'인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝]OpenCV Python의 Filter (1) | 2024.07.30 |
|---|---|
| [딥러닝]Positional Encoding (with Positional Embedding) (0) | 2024.07.25 |
| [딥러닝] 이미지 인식, 분류, 분할 - 컴퓨터 비전 (1) | 2022.03.15 |


